- Introduction
- What is a Large Language Model (LLM)?
- Core Ideas Behind LLMs
- Inference: How LLMs Generate Text
- Limitations and Nuances
- Conclusion
Large Language Models (LLMs) have emerged as the centerpiece of the AI revolution. They're powering everything from ChatGPT to search engines, autonomous agents, and coding copilots. But despite their widespread adoption, many technical professionals still treat them as opaque black boxes.
This article aims to demystify LLMs for engineers and AI-curious professionals by diving into:
- What LLMs really are
- How they are trained and optimized
- What makes them powerful (and where they fall short)
- Architectural nuances and scaling laws
- Practical applications and deployment considerations
At a high level, an LLM is a neural network trained to predict the next token (word or subword) in a sequence of text, given the previous tokens. The model learns statistical patterns, associations, and structure in natural language to generate coherent, contextually relevant text.
LLMs are probabilistic sequence models trained on massive corpora of human language to learn the conditional probability distribution
P(next_token | previous_tokens).
LLMs typically fall under the broader category of transformer-based architectures, trained using self-supervised learning.
To truly understand LLMs, we must understand the transformer architecture, tokenization, self-supervised learning, and attention mechanisms.
Text is broken down into smaller units called tokens. These could be words, characters, or subwords depending on the tokenizer (e.g., Byte-Pair Encoding or SentencePiece).
Input: "Artificial intelligence is powerful."
Tokens: ["Artificial", "$intelligence", "$is", "$powerful", "."]Tokenization is non-trivial because it impacts:
- Vocabulary size
- Generalization ability to unseen words
- Efficiency of training
Introduced by Vaswani et al. in 2017, transformers discard recurrence (used in RNNs) and instead use self-attention to model relationships between all tokens in a sequence. The Key Components of a Transformer Decoder Block:
- Multi-head Self-Attention: Allows the model to attend to different parts of the input simultaneously by computing attention in multiple subspaces and then combining the results.
- Layer Normalization: Normalizes activations across each token’s features to stabilize and speed up training by reducing internal covariate shift.
- Feed-Forward Networks: Position-wise MLPs applied to each token independently to add non-linearity and enable complex transformations after attention.
- Residual Connection: Adds the original input of a sub-layer to its output, helping with gradient flow and allowing deeper networks to train effectively.
- Positional Encodings: Injects information about token positions into the model since transformers lack inherent sequence ordering due to parallel processing.
LLMs like GPT are built from stacked decoder-only transformer blocks.
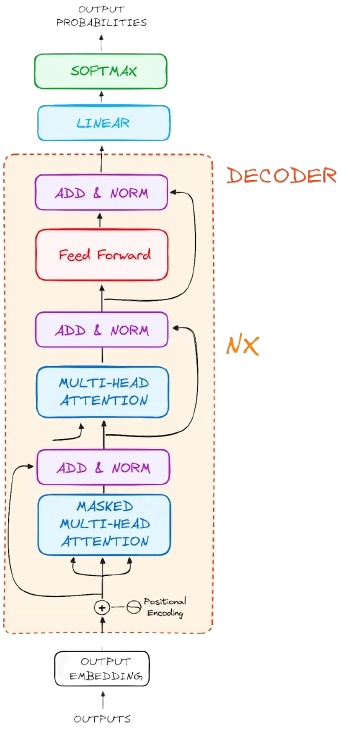 Image attributed to
datacamp.com
Image attributed to
datacamp.com
This enables transformers to:
- Understand long-range dependencies in text
- Process all tokens in parallel (unlike RNNs)
- Scale efficiently with compute
Self-attention allows the model to weigh the importance of each token relative to others in the sequence. For each token, it computes attention scores with every other token.
For token "is", attend to:
"Artificial": 0.2
"intelligence": 0.6
"is": 0.1
"powerful": 0.8The result is a contextual representation for every token that captures meaning based on context.
LLMs are trained using causal language modeling (CLM) or masked language modeling (MLM):
- CLM (e.g., GPT): Predict the next token in sequence. Autoregressive.
- MLM (e.g., BERT): Predict missing/masked tokens. Bidirectional context.
LLMs like GPT use a causal setup:
Input: "The sky is"
Target: "blue"
Model learns: P("blue" | "The sky is")Training generally involves:
- Massive corpora (Common Crawl, books, code, Wikipedia)
- Billions of parameters
- GPUs/TPUs at scale (entire clusters of high-performance hardware)
- Gradient descent with Adam optimizer
Model Parameter Count: The "large" in LLM refers to the number of trainable parameters, often in the billions or trillions.
- GPT-2 1.5B
- GPT-3 175B
- GPT-4 ~1T (estimated)
- Claude Opus 200B+
- LLaMA 3 70B–400B
As models scale:
- Performance improves on downstream tasks
- Emergent behaviors appear (e.g., in-context learning, reasoning, code generation)
- Generalization increases without explicit fine-tuning
This trend is described by scaling laws (Kaplan et al., 2020), showing log-linear improvements with increased data, parameters, and compute.
LLMs are often pretrained on generic corpora and then further adapted:
Fine-tuning
- Supervised training on a domain-specific dataset to adjust the model weights
- E.g., medical LLMs, legal-specific LLMs, coding-specific LLMs
Instruction Tuning
- Instruction-response pairs are datasets where each example consists of: a. An instruction (a natural language command or task description) and A response (the desired output or answer to that instruction)
- Fine-tune with instruction-response pairs which makes models better at following human instructions better in a generalizable way
- E.g., Fine-tuned language network (FLAN)
Reinforcement Learning from Human Feedback (RLHF)
- Humans rate model completions to create a dataset of human preferences
- Reward model trained to rate the quality of model completions
- LLM updated via Proximal Policy Optimization (PPO)
- Improves alignment and usefulness of the model to human preferences
- E.g., Used extensively in ChatGPT and Claude.
At inference time, the model generates tokens one at a time, autoregressively:
- Tokenization: The input prompt is encoded into a sequence of tokens using the model's tokenizer
- Context Processing: The model processes the current context (all previous tokens) to predict probability distribution for the next token
- Token Selection: A token is sampled from the probability distribution using configured sampling parameters
- Context Update: The selected token is appended to the context window
- Iteration: Steps two to four repeat until a stopping condition is met (e.g., max length, end token, or other criteria)
Sampling Strategies
- Greedy decoding: Always pick highest-probability token (can be repetitive).
- Top-k sampling: Sample from top-k most likely tokens.
- Top-p (nucleus) sampling: Sample from smallest set whose cumulative probability exceeds p.
- Temperature: Controls randomness (lower = deterministic, higher = diverse).
Despite their power, LLMs are not silver bulllets, they have their limitations:
- No true understanding: Models mimic patterns, not meaning.
- Hallucinations: Confidently generate false or misleading information.
- Context window limits: Input length constraints (e.g., 8k–128k tokens).
- Bias & toxicity: Inherited from training data.
- Compute cost: Training and inference are expensive and carbon-intensive.
LLMs have a wide range of applications and are reshaping industries in a variety of ways:
- Dev Tools: GitHub Copilot, Cursor, Devin
- Customer Support: Chatbots, summarizers, ticket triage
- Search & Retrieval: LLMs + RAG systems
- Education: Tutoring, content generation
- Enterprise Agents: Workflow automation, data analysis, and more
LLMs are increasingly paired with tools, APIs, memory, and planning modules to become autonomous agents.
- Latency: Token-by-token generation is slow. This is a trade-off for the model's ability to generate coherent text.
- Memory usage: Inference can consume tens of GBs.
- Cost: API or hosted models can be expensive at scale.
- Context management: Strategies like summarization or retrieval (RAG) needed for long interactions.
- Security: Prompt injection, data leakage, model inversion attacks. Using the model in a secure way is a complex problem.
LLMs represent a new abstraction layer in computing—models that can interpret, generate, and reason with natural language. For engineers, this isn't just about language, it's about building systems that can learn behaviors from data without explicit programming.
We’re just beginning to explore what these systems can do when fused with memory, tools, agents, and multimodal inputs. The future isn’t just large language models—it’s language-native computation.