- Synopsis
- The Problem
- Why Self-Host
- The Stack
- Architecture
- The Pipeline
- Deepgram SDK 6.x: Adapting to a Breaking Change
- Dynamic Mode Switching
- Transcript Persistence
- Structured Logging
- Configuration: Fail Loud, Fail Early
- Latency Budget
- What This System Does Not Do
- Lessons
- Conclusion
I built a self-hosted voice AI agent that conducts technical interviews in real time. It replaced a hosted voice AI platform with a purpose-built Python microservice. This post covers the architecture, the decisions behind it, and the problems I had to solve.
The product is a technical interview platform. A candidate joins a room, and an AI interviewer conducts a structured voice interview — introduction, technical questions, a coding problem, and wrap-up.
The first version used a hosted voice AI platform. It worked for the conversational parts. It broke down at a specific requirement: coding mode.
When a candidate is writing code, the interviewer needs to stay silent. Not for a second or two — for up to 90 seconds. And then, if the candidate hasn't spoken, the interviewer should check in: "Do you need any help with your approach?"
The platform's VAD (Voice Activity Detection) silence threshold is not configurable at runtime. You set it once. If you set it to 90 seconds, the normal Q&A becomes unusable — the agent waits a minute and a half after every sentence before responding. If you set it to 1.2 seconds, the agent interrupts the candidate mid-thought during coding.
This is the kind of requirement that forces you off a hosted platform. Once you need runtime control over one parameter, you discover you want control over several more.
The decision to self-host was not about the hosted platform being bad. It was about the requirements not fitting the abstraction layer that any hosted platform provides.
Runtime-configurable VAD. The central server sends a mode switch command (CODING or CONVERSATIONAL) via Redis. The agent updates the VAD silence threshold on the live pipeline without restarting anything. This is not possible through a third-party API that exposes VAD settings as static configuration.
Interruption control. When the candidate speaks while the agent is talking, the system needs to:
- stop TTS playback immediately
- discard the buffered LLM response
- transcribe the interruption
- re-generate from the updated context
Hosted platforms expose some barge-in settings, but not the full pipeline control needed to guarantee this behavior.
Transcript ownership. Every utterance — user and agent — is POSTed to our central server the moment it is finalized. No polling a vendor API. No batch exports. No webhook delays. The agent produces transcript entries; the central server persists them. The data never sits in a third party's storage.
Latency. A hosted platform adds a network hop between the media server and the AI pipeline. Self-hosting LiveKit on the same infrastructure as the rest of the application removes that hop. For a system targeting sub-800ms ear-to-ear response time, every hop matters.
Cost at scale. Per-minute pricing on hosted platforms exceeds the combined cost of Deepgram, Gemini, and Cartesia API calls when you run them directly. The operational overhead of self-hosting is real, but the per-session cost is lower. Also, with the accelerator credits, the infra costs effectively goes to zero.
The trade-off is straightforward: you own the full stack, you maintain the full stack. For this use case, that was the right call.
| Layer | Choice | Why |
|---|---|---|
| Transport | LiveKit (self-hosted) | Open-source WebRTC server. Self-hostable. Python SDK with first-class support. |
| Pipeline | Pipecat | Frame-based pipeline framework for voice AI. Handles the orchestration of VAD → STT → LLM → TTS without writing the plumbing from scratch. |
| VAD | Silero VAD | Runs locally, no API call. ~1-3ms per audio frame on CPU. Parameters are reconfigurable at runtime. |
| STT | Deepgram Nova-2 | Streaming WebSocket API. Low latency. Supports interim results for live captions. |
| LLM | Gemini 2.0 Flash | Fast time-to-first-token (~200-400ms). Streaming output. |
| TTS | Cartesia Sonic-2 | Low time-to-first-byte (~100-150ms). Streaming audio output. |
| Signaling | Redis Streams | Reliable ordered messaging with consumer groups and explicit acknowledgment. |
Python 3.11, asyncio throughout. The agent runs as a standalone service, exposing APIs only to the internal system.
Why Pipecat
Voice AI pipelines have a specific set of problems: frame routing between processors, backpressure management, interruption handling (stopping TTS mid-playback when the user speaks), and VAD integration. Writing this from scratch is doable but error-prone. Pipecat provides typed frames, a processor chain, and built-in interruption support.
The framework is opinionated about the processing model — data flows through a linear sequence of frame processors — but not opinionated about which services you use. Swapping Deepgram for Whisper, or Gemini for Claude, means changing one service class instantiation. The pipeline structure stays the same.
Why Redis Streams (Not Pub/Sub, Not a Message Queue)
The central server needs to tell the agent to start sessions, switch modes, and terminate. The agent needs to tell the central server when sessions end.
Redis Pub/Sub was the first thought. The problem: Pub/Sub is fire-and-forget. If the agent is restarting when the central server publishes a START_SESSION command, the message is lost. For a system where sessions represent scheduled interviews with real candidates, losing a start command is not acceptable.
A full message queue (RabbitMQ, SQS) would work but adds operational complexity for a problem that does not need it. The message volume is low (a few messages per session), and the durability requirements are modest (messages matter for minutes, not days).
Redis Streams hit the middle ground: messages are persisted, consumer groups provide exactly-once delivery semantics with explicit acknowledgment (XREADGROUP / XACK), and the operational footprint is zero additional services — Redis is already in the stack.
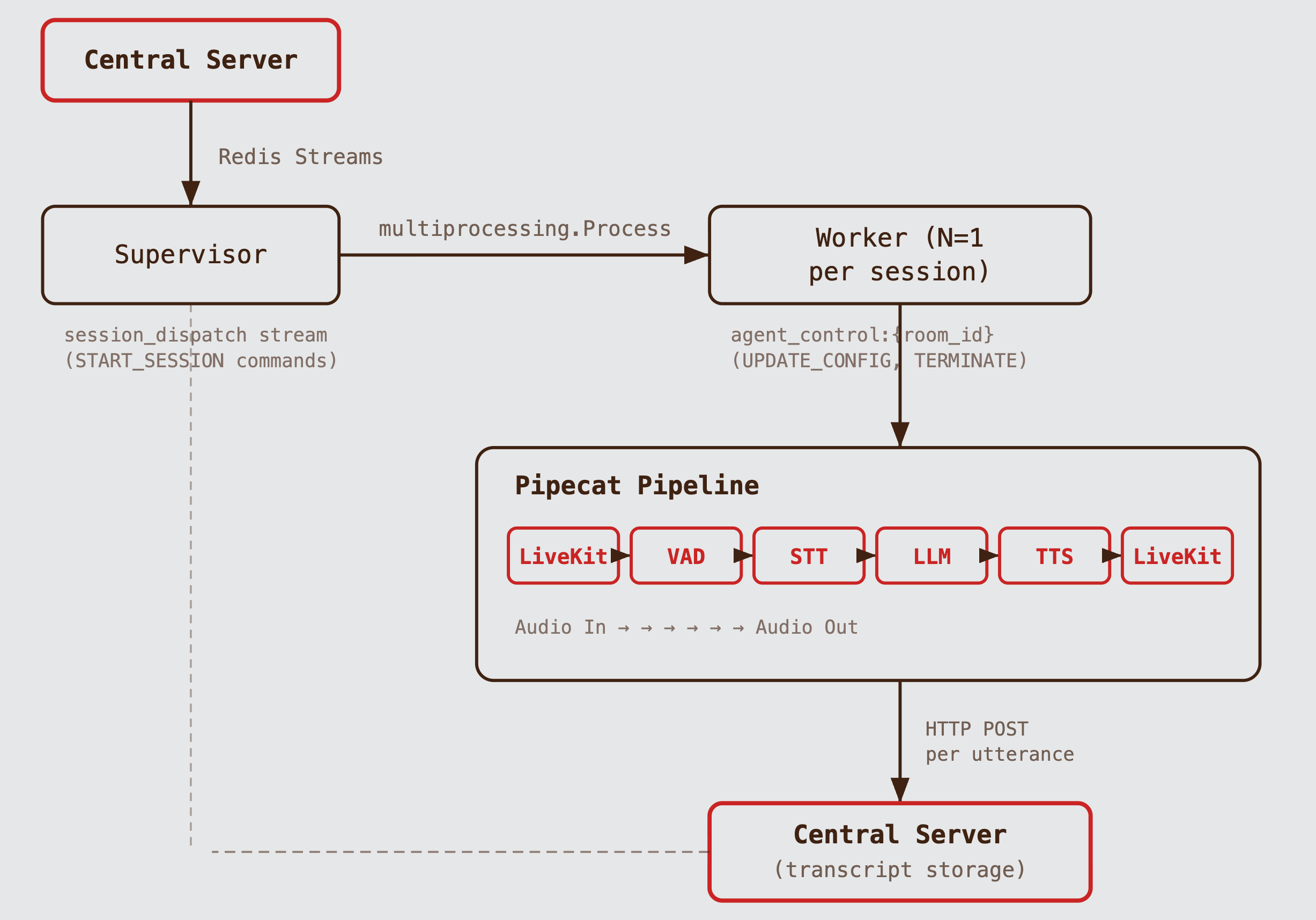
The system has two process types: one supervisor and N workers. The central server never talks to the agent directly. All communication flows through Redis Streams. If the agent crashes, unacknowledged messages remain in the stream and can be redelivered. If the central server is down, the agent logs warnings for failed transcript POSTs but keeps running.
Why Processes, Not Threads
Each interview session runs as a separate OS process (multiprocessing.Process). Not a thread. Not a coroutine sharing an event loop with other sessions.
The reason is Silero VAD. It runs PyTorch inference on every audio frame — CPU-bound work that takes 1-3ms per frame. Python's GIL serializes CPU-bound work across threads. Two concurrent sessions in the same process would contend on the GIL, and VAD latency would double.
Separate processes each get their own GIL and run VAD in true parallel.
The secondary benefit is fault isolation. If a session crashes — a malformed audio frame, an unhandled exception in the pipeline — it takes down one OS process. Other sessions are unaffected. The supervisor detects the dead process and cleans up.
The cost is memory. Each worker process uses ~50-80MB (Python runtime + PyTorch model + pipeline state + LLM context). For the expected concurrency range (tens of concurrent sessions, not thousands), this is acceptable. If it were not, the architecture would need to change — either offloading VAD to a dedicated service or using a language without a GIL.
The Supervisor
The supervisor is a single asyncio loop that does three things:
- Reads
session_dispatchviaXREADGROUPwith a 2-second blocking timeout. - Spawns worker processes when
START_SESSIONarrives. - Reaps dead workers on every iteration, cleaning up PID and room mappings.
If a second START_SESSION arrives for the same room (a retry, or a rapid reconnect), the supervisor terminates the old worker before spawning a new one. The escalation is SIGTERM, wait 5 seconds, SIGKILL. This prevents orphaned workers consuming resources for rooms that have moved on.
Graceful shutdown on SIGTERM: the supervisor sends SIGTERM to all live workers, waits 5 seconds for graceful exit, then sends SIGKILL to anything still running.
The Worker
Each worker runs three concurrent async tasks:
- Pipeline runner — the Pipecat pipeline processing audio frames.
- Control listener — reading
agent_control:{room_id}for mode switches and termination commands. - Transcript poster — firing HTTP POSTs to the central server (as a background concern, not a task you
await).
The coordination between the pipeline runner and the control listener uses asyncio.wait with FIRST_COMPLETED. If either task finishes, the other is cleaned up. This handles two failure modes:
- Redis dies → control listener exits with a failure flag → pipeline is terminated via
EndFrame. - Participant leaves → pipeline ends naturally → control listener is cancelled.
In both cases, a SESSION_ENDED event is published to Redis and the transcript poster is drained (up to 10 seconds for pending HTTP calls, then force-cancel).
The data flow through the Pipecat pipeline:
LiveKit Audio In → Silero VAD
→ Deepgram STT → [User Transcript Tap]
→ Context Aggregator → Gemini LLM
→ [Agent Transcript Tap] → Cartesia TTS → LiveKit Audio OutThe "transcript taps" are frame processors inserted at two points in the chain. They intercept frames without modifying them, forwarding transcript data to both the frontend (via LiveKit data channel) and the central server (via HTTP POST).
Barge-In
The pipeline runs with allow_interruptions=True. When Silero VAD detects speech while TTS audio is playing:
- TTS playback stops immediately.
- Any buffered LLM tokens are discarded.
- The new user speech is transcribed.
- The LLM generates a fresh response with the interruption in context.
This is handled by Pipecat's frame routing — no custom interruption logic was needed. The flag enables it; the framework handles the mechanics.
The Greeting Problem
When a candidate joins the room, the agent needs to speak first. There is no user audio to trigger the pipeline. The solution is a LiveKit transport event:
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant_id):
await task.queue_frames([
LLMMessagesAppendFrame(
run_llm=True,
messages=[{
"role": "user",
"content": "The candidate has just joined. Greet them warmly and ask them to introduce themselves.",
}],
)
])A synthetic message is injected into the LLM context, and run_llm=True triggers an immediate response. The candidate hears a greeting within a second of joining.
Pipecat's built-in Deepgram service requires deepgram-sdk ~= 4.7.0. The project uses deepgram-sdk 6.0.1 — a Fern-generated SDK with a completely different API surface. The class names, method signatures, and connection patterns are all different. Downgrading to 4.x was not an option (it would mean pinning a legacy SDK and losing future updates).
The solution was a custom STT adapter (~200 lines) that extends Pipecat's STTService base class and manages the Deepgram WebSocket connection directly.
The key architectural decisions in the adapter:
Separate reader task. Pipecat's STTService expects run_stt(audio) to be an async generator that yields transcription frames. But Deepgram's streaming API is bidirectional: you send audio on one channel and receive results on another. The adapter sends audio in run_stt (yielding nothing) and receives results in a background task that pushes frames directly into the pipeline.
Disabled Deepgram endpointing. Both Silero VAD and Deepgram can detect when the user stops speaking. Using both creates a race condition: Deepgram might fire its endpoint before the local VAD, or vice versa, causing duplicate or out-of-order finalization. The solution is to disable Deepgram's endpointing entirely and use only the local VAD. When VAD detects silence, the adapter sends a Finalize message to Deepgram, which flushes its buffer and returns the final transcript.
# When VAD says the user stopped speaking:
self.request_finalize()
await self._socket.send_finalize()
# When Deepgram responds with the finalized transcript:
if response.from_finalize:
self.confirm_finalize()
await self.push_frame(TranscriptionFrame(text=text, ...))This request_finalize / confirm_finalize handshake is part of Pipecat's STT contract. It ensures the pipeline knows when the final transcript for an utterance has arrived and can safely pass it to the LLM.
Reconnection with exponential backoff. WebSocket connections drop. The adapter detects a closed socket, schedules a reconnection task with exponential backoff (2s, 4s, 8s, ..., capped at 30s), and gives up after 5 attempts. During reconnection, audio frames are silently dropped — a brief gap in transcription is preferable to a crashed pipeline.
This is the feature that motivated the entire project. The system supports two interaction modes that can be switched at runtime without restarting the pipeline.
Conversational mode: VAD silence threshold is 1.2 seconds. The agent responds promptly after the candidate finishes speaking. Normal interview behavior.
Coding mode: VAD silence threshold increases to 3.0 seconds. A system message is injected into the LLM context: "User is now in CODING mode. Only respond when they speak to you. Do not initiate conversation." A silence timer starts — after a configurable period (default 90 seconds), the agent checks in with the candidate.
The mode switch is triggered by the central server via Redis:
{
"command": "UPDATE_CONFIG",
"payload": { "mode": "CODING", "silence_timeout": 90 }
}The control listener applies the change in four steps:
- Update VAD parameters on the live transport (no pipeline restart).
- Inject a system message into the LLM context (
run_llm=False— no immediate response). - Start or cancel the silence check-in timer.
- Update the transcript poster's current mode (so transcript entries carry the mode label).
The Silence Timer
In CODING mode, a background async loop sleeps for N seconds, then injects a check-in prompt into the LLM:
The candidate has been silently coding for a while. Briefly check in — ask if they need help or have questions about their approach. Keep it to one short sentence.
The LLM generates a brief response, which flows through TTS to the candidate. If the candidate speaks before the timer fires, the normal pipeline handles it — the timer is independent.
When the mode switches back to conversational, the timer is cancelled.
The 90-Second Edge Case
There is a subtle problem with long silence thresholds. If the candidate finishes coding in 10 seconds and waits for the agent, the agent stays silent for another 80 seconds (or however long until the timer fires). The candidate thinks the system is broken.
The mitigation is external to the agent: the frontend detects user actions (clicking "Run Code" or "Submit") and the central server sends an immediate UPDATE_CONFIG back to conversational mode. The agent's VAD threshold drops to 1.2 seconds, and the next silence triggers a response.
The agent does not need to know about UI events like button clicks or navigation. However, it does receive coding events — what the candidate types in the editor — so it can reason about their approach and ask relevant follow-up questions. Beyond that, it only needs to respond to mode switch commands. This keeps the boundary clean.
The agent is a transcript producer, not a store. It has no database. Every finalized utterance is POSTed to the central server immediately:
{
"session_id": "uuid",
"role": "user",
"text": "I think I would use a hash map here.",
"start_time": "2026-03-03T10:00:00.000Z",
"end_time": "2026-03-03T10:00:03.200Z",
"vad_mode": "CONVERSATIONAL",
"sequence": 4
}The central server owns the schema, persistence, and any computed fields. The agent is purely a data source.
Fire-and-Forget, By Design
Transcript POSTs are non-blocking. They are scheduled as asyncio.create_task and tracked in a pending set. The pipeline never waits for a POST to complete. If the central server is slow or down, the POST fails, a warning is logged, and the pipeline continues.
This is a deliberate trade-off: pipeline latency is prioritized over transcript completeness. A 200ms delay from a slow HTTP call would be audible to the candidate. A missing transcript entry can be recovered. A queue-based approach (e.g. an in-memory buffer with retry and guaranteed delivery) would solve the lost transcript problem entirely, but that complexity is kept for later — pending analysis of whether transcripts are actually being lost in practice at a rate that justifies it.
Crash Recovery
If the agent process crashes mid-utterance, the current transcript entry is lost — end_time and text were never sent. The recovery mechanism: on every session startup, before the pipeline is built, the worker POSTs to mark-incomplete on the central server. This flags any orphaned entries from a prior crash of the same session ID, so downstream consumers (summaries, analytics) know the transcript may be incomplete.
The agent does not retry failed POSTs, does not maintain a local write-ahead log, and does not implement exactly-once delivery. The mark-incomplete + sequence number approach is simpler and sufficient for the use case.
Every log line is structured JSON, emitted to stdout. The logging infrastructure uses Python's standard logging module with python-json-logger and contextvars.
The key design: session_id and room_id are set once per worker process via contextvars.ContextVar. A custom logging.Filter reads them from the context and attaches them to every log record. No function in the codebase passes correlation IDs as arguments.
session_id_var: contextvars.ContextVar[str] = contextvars.ContextVar(
"session_id",
default="-",
)
room_id_var: contextvars.ContextVar[str] = contextvars.ContextVar(
"room_id",
default="-",
)Every log record carries: timestamp_utc (ISO-8601), level, component (e.g., stt, pipeline, control, redis), session_id, room_id, and message. This structure is compatible with any log aggregation tool (Loki, Datadog, CloudWatch) without transformation.
Adding a new log sink — say, Sentry for errors — means adding one logging.Handler in one file. No call site anywhere in the codebase changes.
Why contextvars Over Passing IDs Explicitly
In a multi-process architecture where each process handles exactly one session, the session context is process-global. contextvars captures this naturally: set once at process start, available everywhere. The alternative — passing session_id and room_id through every function signature from the top-level entry point to the deepest logger call — is noisy and error-prone. One missing parameter means one log line without correlation data, which makes debugging concurrent sessions difficult.
All configuration is loaded from environment variables at startup. Every required variable is checked upfront. If any are missing, the process exits immediately with a list of all missing keys — not one at a time.
@dataclass(frozen=True)
class Config:
livekit_url: str
deepgram_api_key: str
# ... 9 more fields ...The frozen=True on the dataclass prevents accidental mutation. The config object is created once in the main process and passed to worker processes via multiprocessing.Process arguments (serialized by pickle). There is no global mutable config state.
Why not a YAML/TOML config file? Environment variables are the standard interface for containerized deployments. The config surface is small (11 values). There is no nesting, no conditional logic, no per-environment overrides. Env vars are the simplest tool that works.
The target is under 800ms from the moment the user stops speaking to the moment they hear the first audio of the response. The pipeline is fully streaming — the LLM streams tokens to TTS, and TTS streams audio to LiveKit. At no point does the system wait for a complete response before starting output.
| Stage | Time | Notes |
|---|---|---|
| VAD stop detection | ~150ms | stop_secs=1.2 in conversational mode. Lower values trigger on mid-sentence pauses. |
| Deepgram finalize | ~80-150ms | Time for Deepgram to return the final transcript after receiving the finalize signal. |
| LLM time-to-first-token | ~150-300ms | Gemini 2.0 Flash. Varies with prompt length and server load. |
| TTS time-to-first-byte | ~80-120ms | Cartesia Sonic-2. |
| Network (LiveKit → client) | ~10-30ms | Depends on deployment topology. Self-hosted LiveKit minimizes this. |
In practice, observed end-to-end latency is often lower than the sum of worst cases — typically 500-700ms. The stages overlap due to streaming (LLM tokens flow into TTS before the full response is generated), and hot connections to Deepgram, the LLM, and Cartesia avoid repeated handshake overhead. The VAD threshold remains the largest contributor and the most tunable. Reducing stop_secs from 1.2 to 0.8 shaves 400ms off the response time but causes the agent to "jump in" during natural speech pauses.
No echo cancellation. AEC is handled by the LiveKit client SDK on the frontend (browser-native). Attempting echo cancellation in Python server-side would add latency and produce worse results than WebRTC's built-in AEC.
No automatic scaling. Each supervisor manages workers on a single machine. Horizontal scaling means deploying more supervisor instances that share the same Redis consumer group. Redis Streams' consumer group model supports this natively — each START_SESSION is delivered to exactly one supervisor.
No LLM provider lock-in. Swapping Gemini for OpenAI or Anthropic means changing one service class instantiation. The pipeline structure, transcript forwarding, mode switching, and signaling are all LLM-agnostic.
No direct database access. The agent does not know what database the central server uses. It does not run migrations. It does not manage connection pools. It POSTs JSON over HTTP. This boundary is deliberate — the agent is a media worker, not a CRUD service.
Pipecat does most of the work. The pipeline framework handles frame routing, interruption mechanics, and VAD integration. Without it, the project would be 3-5x larger and significantly more fragile. The framework's abstraction layer (typed frames, processor chains) is well-suited to this problem.
The hard part is not the AI. The STT, LLM, and TTS services are API calls. The hard part is the integration: making VAD, STT, LLM, and TTS work together with low latency, handling mode switches without restarting the pipeline, maintaining reliable signaling, and ensuring graceful shutdown under every failure mode (Redis down, central server down, participant disconnects, process crashes).
SDK version mismatches are a real problem. The Deepgram SDK 6.x incompatibility with Pipecat's built-in service cost multiple days. The ecosystem of voice AI libraries is young, and breaking changes between major versions are common. The custom adapter works, but it is 200 lines of code that exists solely because two libraries disagree on a dependency version.
Fire-and-forget with recovery beats guaranteed delivery. The transcript posting system does not guarantee every utterance reaches the central server. It trades completeness for latency, with mark-incomplete as the safety net. For a real-time voice pipeline, this is the right trade-off. Guaranteed delivery would require a local write-ahead log, retry queues, and idempotency keys — complexity that adds latency to the hot path for a benefit that matters only in edge cases.
Process-per-session is expensive but correct. The memory cost is real (~50-80MB per worker). But the alternatives — thread-per-session with GIL contention, or all-sessions-in-one-process with shared-nothing coroutines — create worse problems. The GIL makes CPU-bound VAD incompatible with threading. Coroutines sharing a process would require careful isolation of all mutable state (LLM context, VAD state, transcript sequence numbers) with no fault isolation between sessions. Processes give you isolation for free.
The system works. It conducts technical interviews with sub-second response times, handles mode switches mid-conversation, survives component failures gracefully, and costs less per session than the hosted platform it replaced.
The total investment was about 800 lines of Python and the operational commitment to maintain a self-hosted LiveKit and Redis deployment. Whether that trade-off makes sense depends entirely on whether your requirements fit within the configuration surface of hosted platforms. If they do, use the hosted platform. If they do not — and runtime-configurable VAD was the requirement that did not fit for us — building your own is a viable path.